
Video Generation with TimeCycleGAN
During my master’s thesis in Data Engineering and Analytics, I developed a novel general-purpose loss for temporal consistency in generative adversarial video generation. Unlike existing methods, our TimeCycle loss has no task-specific model assumptions and can be easily applied to arbitrary GANs in any domain.
Based on our novel loss, we proposed the TimeCycleGAN meta-architecture for temporally-consistent video generation. We applied the meta-architecture to two basic methods for paired and unpaired image-to-image translation and demonstrate significant improvements in temporal consistency, by up to 63 percent.
Our models can generate photorealistic, temporally-consistent street-scene videos in both paired and unpaired settings, and achieve quantitative video quality and temporal consistency scores comparable to the respective task-specific state-of-the-art.
Project Overview
- Duration: September 2019 to July 2020 (11 months)
- Team: Me and supervising prof.
- My Responsibilities: Research; model design, implementation, training, and evaluation
- Full Thesis (450MB): http://fa9r.com/files/timecyclegan.pdf
- Source Code: https://github.com/fa9r/TimeCycleGAN
TimeCycleGAN: Temporally Consistent Video Generation
Before we introduce our TimeCycle loss, let’s have a look at the other two modifications that are needed to form our TimeCycleGAN meta-architecture.
Let us assume we start with an arbitrary per-frame GAN model consisting of a generator G and discriminator D trained in an adversarial manner to optimize the standard GAN objective. We visualize such a GAN below, where we use convolutional architectures to illustrate both G and D.
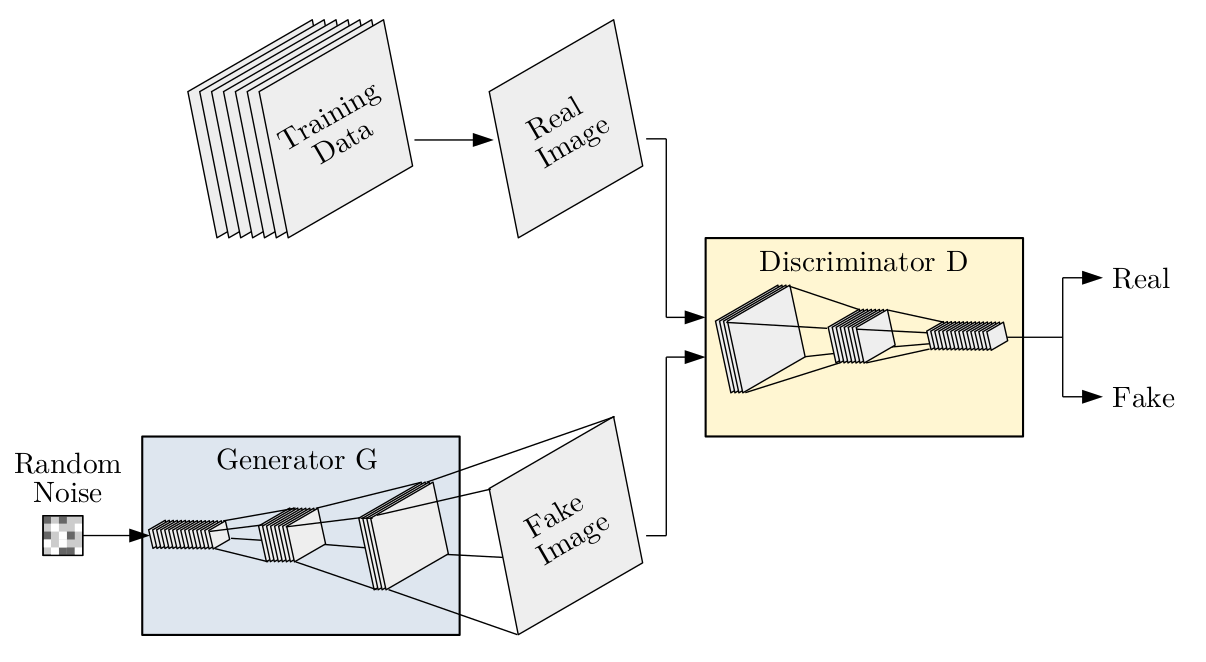
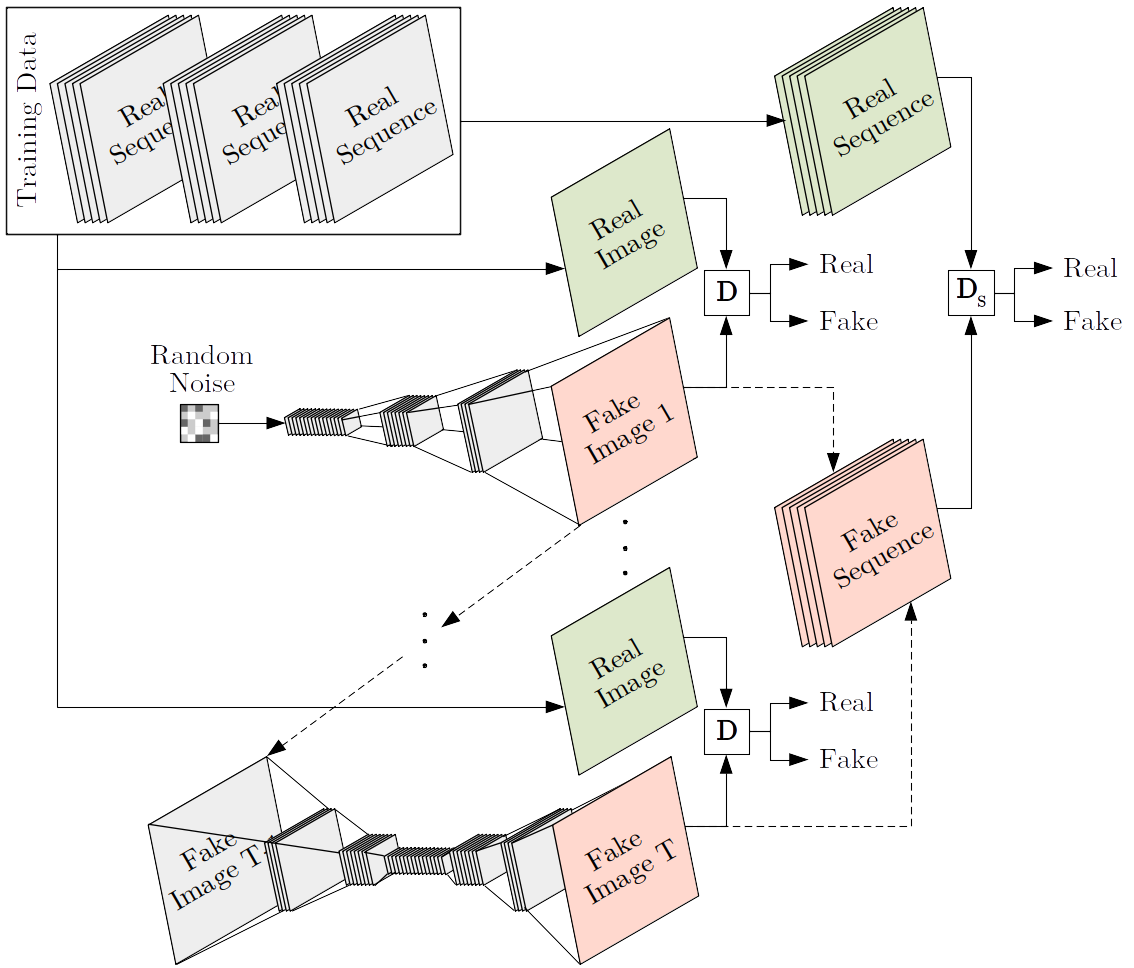
We argue that, in order to learn temporal consistency, there needs to be a correlation between generated frames in the generation process, which we propose to establish with a recurrent generator design that generates subsequent frames based on the previous outputs.
Furthermore, we use an additional sequence discriminator that is applied only once on the entire sequence, as opposed to the per-frame discriminator that is applied to every frame separately. In practice, we use both per-frame and sequence discriminators.
This sequential GAN design with recurrent generator, per-frame discriminator, and sequence discriminator is shown below.
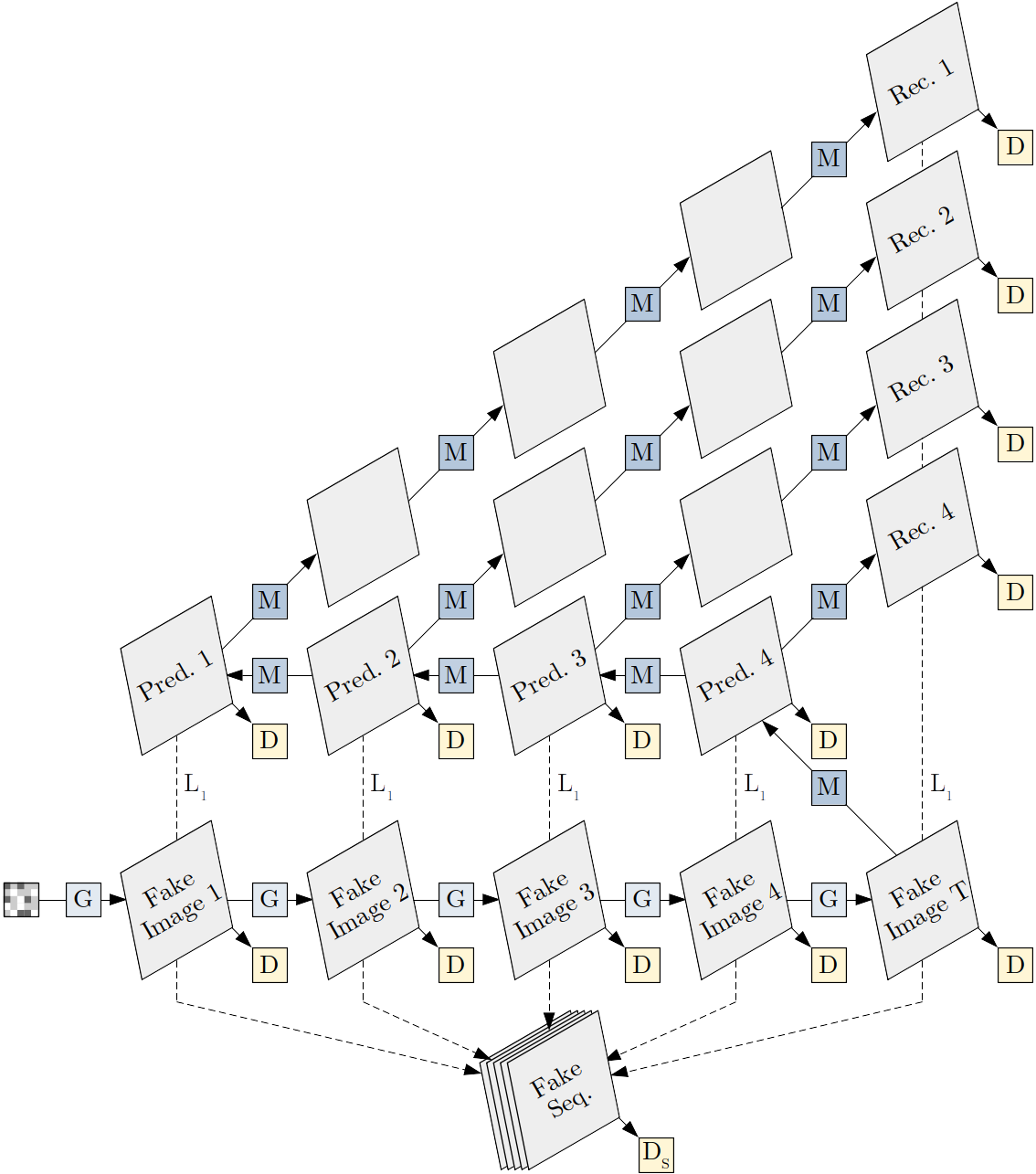
The core contribution of our approach now is the TimeCycle loss, which we add on top of the previously shown architecture.
The idea behind this loss is to train the GAN jointly with a motion model, enforce temporal consistency of the motion model via a temporal cycle-consistency loss, and then pass the temporal consistency to the GAN.
What this means exactly is somewhat difficult to explain without making this post unbearably long. Said shortly:
- The motion model is a simple neural network that is trained to shift frames according to the natural movement in the specific domain (i.e., given one frame, how will the next one look like?),
- The temporal cycle-consistency constraint requires it to additionally reconstruct its input through a backward-forward generation cycle (i.e., if we take an image, predict the previous one, and then the next one of that one, will we get the initial image back?),
- The temporal consistency is passed to the GAN by applying the motion model to its generations and adding similarity constraints between frames corresponding to the same time steps (i.e., if we take one of the later frames of a sequence generated by the GAN and shift that frame backward in time, is it the same as the corresponding previous frame of the generated sequence?).
What exactly is happening is probably still not clear, I know. The only important thing to know really is that we stick another neural network on top of the GAN and train them jointly without making any assumptions on the GAN architecture, which allows the loss to be general-purpose.
If we visualize our full meta-architecture applied to the basic GAN from before, it will look like what you can see below. For all TimeCycle loss parts, we found the L1 constraint to work best.
As emphasized previously, our proposed TimeCycle loss is a general-purpose approach that can be applied to arbitrary GAN models. Furthermore, adding the TimeCycle loss to an existing PyTorch GAN model is very easy and does not require any modifications to the model itself if the model implementation follows a few common assumptions. In my thesis, a detailed guide explains how the TimeCycle loss can be added to custom GAN models in as few as 10 lines of code.
Experiments
To evaluate our meta-architecture, we applied it to two methods for paired and unpaired image-to-image translation: pix2pix and CycleGAN. We then compared our resulting models both to the corresponding baseline and the task-specific state-of-the-art (vid2vid and RecycleGAN respectively).
For all quantitative evaluations and ablations, we used a total of four metrics, two of which measure temporal consistency (tLP and tOF) and two that measure video quality (FID and LPIPS). For all metrics, lower means better.
Paired Video Generation
For the paired setting, we wanted to generate realistic street scene videos from a sequence of semantic segmentation maps. To train our models, we used the Cityscapes dataset, specifically the auxiliary video sequences, for which we obtained semantic segmentation maps by inferencing a DeepLabv3 network.
To evaluate our model, we conducted a quantitative comparison of our method, the baseline method pix2pix, and the state-of-the-art method vid2vid. The comparison results are shown below.

The difference between our two methods TCGAN-P and TCGAN-P++ is that the latter uses additional feature matching and a perceptual loss for improved image quality.
As can be seen, all temporal models achieve significantly better scores than pix2pix in both temporal metrics, with TimeCycleGAN-P++ achieving the lowest tLP score, and vid2vid achieving the lowest tOF score. TimeCycleGAN-P is comparable to pix2pix in video quality, while TimeCycleGAN-P++ and vid2vid are significantly better, likely due to the added perceptual loss in both methods. Overall, TCGAN-P++ and vid2vid seem to be the best models, with both achieving the lowest score in two metrics each.
Qualitative results of our stronger model, TCGAN-P++, together with corresponding inputs, are shown below:

Unpaired Video Generation
In the unpaired setting, we tried to learn translations between synthetic and real street scene videos. For the real street scene data, we again used Cityscapes. For the synthetic data, we created our own dataset using the CARLA Simulator.
Qualitative results of our model can be seen in the teaser image and the quantitative comparison to the baseline method CycleGAN and the state-of-the-art method RecycleGAN is shown below.
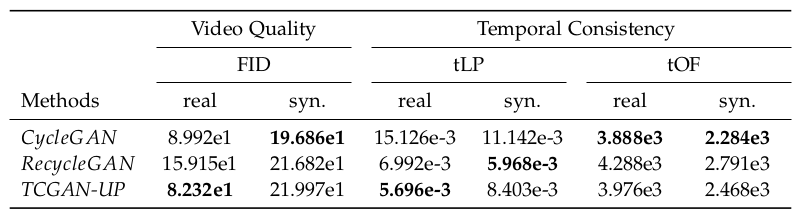
The two numbers per metric represent the different translation directions:
- real: Generation of real images from synthetic images (CARLA → Cityscapes)
- syn.: Generation of synthetic images from real images (Cityscapes → CARLA)
As we see, both RecycleGAN and TimeCycleGAN-UP improve upon the temporal consistency of CycleGAN considerably, with great improvements in tLP scores. However, the video quality of RecycleGAN is worse than that of CycleGAN, and, surprisingly, CycleGAN also has lower tOF scores. Overall, TimeCycleGAN-UP is comparable to CycleGAN in video quality, comparable to RecycleGAN in temporal consistency, and the best performing model overall.
Finally, let’s look at a before-after comparison to see how much better the temporal consistency has become by applying our meta-architecture:

Result
During this project, we have:
- Introduced a new loss for temporal consistency, which has fewer restrictions than existing approaches, and which can be applied to arbitrary GAN models with only a few lines of code,
- Formulated a simple yet powerful meta-architecture for temporally-consistent GANs,
- Designed novel models for paired and unpaired video-to-video translation,
- Improved temporal consistency scores of the baselines by up to 63.5 percent,
- Achieved comparable scores to the task-specific state-of-the-art method in paired video translation and even improved upon the unpaired state-of-the-art.
For more info, please see my full thesis. It additionally contains:
- A more detailed explanation of our method, baseline methods, and state-of-the-art,
- Implementation details, hyperparameters, and a usage guide,
- Further qualitative comparisons,
- Ablation studies,
- A detailed discussion of the metrics used for quantitative comparisons,
- An overview of related work in temporal cycle consistency learning,
- Limitations, possible improvements, and more.
Note that the full thesis contains all results and comparisons as embedded videos, so the file size is huge (442MB). Alternatively, there is also a smaller version (2MB) without videos.
Takeaways
- Recurrent generator designs are currently best suited for video generation.
- Unconditional sequence discriminators perform better than conditional sequence discriminators (especially when combined with our TimeCycle loss).
- The L1 distance is the preferable choice for temporal constraints (both for our TimeCycle loss and the TecoGAN Ping-Pong loss.
- Perceptual losses correlate highly with human perception and can considerably improve the video quality of paired video-to-video translation methods.