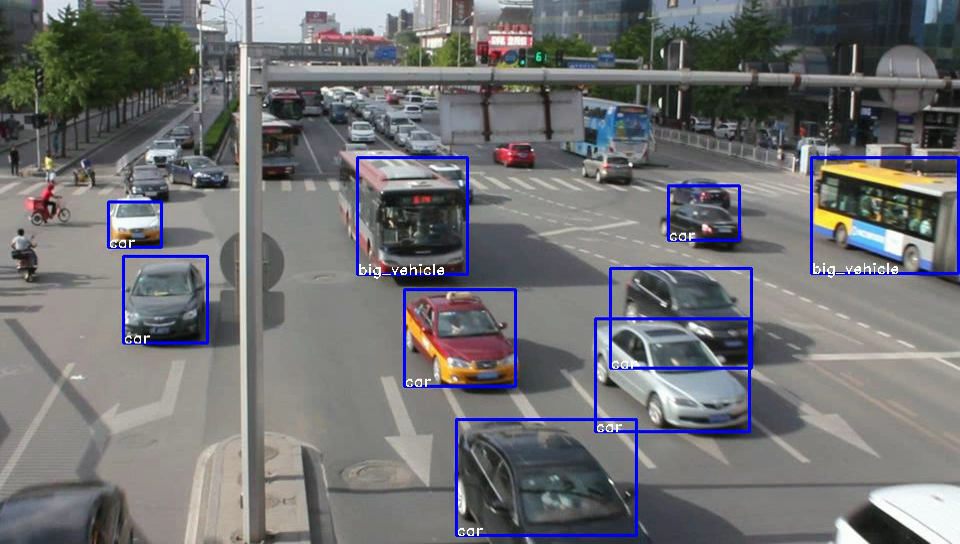
Vehicle Detection in Project Providentia
Project Providentia was a large publicly-funded multi-year project including various large corporations like Huawei and BMW. The goal was to create a digital twin of the entire traffic situation on the German highway A9, which could then be used by assistive systems within cars to visualize oncoming traffic and by autonomous test vehicles for safer and more efficient road planning.
During my bachelor thesis and subsequent working student position at Cognition Factory GmbH, I developed the first version of Providentia’s object detection system, which can reliably detect and classify vehicles at over 50 FPS on an Nvidia P100 GPU and is integrated into a C++/ROS backend.
Project Overview
- Duration: April 2017 to February 2018 (10 months; my involvement only)
- Team: 2 Informatics PhDs, 3 other working students, and me
- My Responsibilities: Object detection research, model development, training, and deployment
Datasets
The goal of my work was to detect vehicles on the German highway A9. However, in the beginning, there wasn’t any data available yet except for one unannotated video that I could use to test my models.
Therefore, I initially tried to train my models on large vehicle datasets like KITTI. However, I found the performance unsatisfying, because the data recorded from within vehicles translated poorly to highway vehicle detection. Subsequently, I analyzed several publicly available highway vehicle datasets regarding quality, size, and similarity to our scenario and experimented with several options.
As the project progressed, I eventually received further real data recorded on the A9 highway. However, none of this data was annotated. Thus, I hand-annotated more than 20000 highway images by manually drawing bounding boxes around all relevant vehicles in addition to labeling their classes. For data safety reasons, all license plates, windows, etc. had to be anonymized as well.
For my final models, I used backbones pretrained on large vision datasets, pretrained the whole models on large publicly available highway datasets, and then fine-tuned them on the hand-annotated real data. To do so, all datasets needed to have a similar labeling style, for which I wrote various conversion scripts.
To achieve the final model performance, it was also necessary to modify and augment the data in creative ways. Interestingly, the data preparation was probably even more impactful than the detection model choice.
Object Detection Models
For my bachelor thesis, I created a 20-page survey of state-of-the-art object detection approaches and corresponding neural network architectures. I then selected the four (in my opinion) most promising methods, trained them on the same highway vehicle data, and compared them regarding inference speed and detection performance as measured by Mean Average Precision.
After the model comparison, we found that all models that were fast enough to run in real-time achieved unsatisfying performance. Thus, we had to build a custom model by either making a fast but weak model stronger or by making a powerful but slow model faster. In the end, we chose the former and carefully tuned the model complexity to be as strong as possible while still barely achieving an inference speed of 50 FPS.
Still unsatisfied, we turned to data tweaking as mentioned above, which led to a huge performance increase and allowed us to achieve both the quality and speed we desired. Additionally, we modified the model to also distinguish between several custom-defined vehicle types and wrote C++/ROS inference code such that it could be integrated into the team’s pipeline.
Result
In the end, we managed to build a detection model that can reliably and correctly detect and classify vehicles at over 50 FPS (see teaser image for results), deployed it in the team’s C++/ROS production pipeline, and documented it properly for handoff.
Takeaways
- For real-world applications, always start by thinking about what the runtime limit of your ML model will be. Then design a model that is as good as possible while still being as fast as needed.
- Data tuning is a highly underrated skill that is rarely taught in machine learning lectures (datasets are usually assumed given). In practice, the right data preparation is key and can be even more impactful than the model choice.
- Datasets for pretraining should be as close to the final task as possible. However, even unrelated datasets are better than nothing, because at least earlier low-level convolution layers can learn meaningful patterns already. Thus, if relevant pretraining data is available but limited, a multi-stage pretraining approach can make sense.